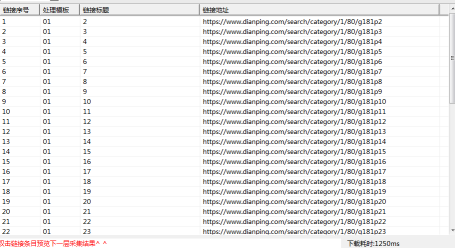
1、 前嗅ForeSpider数据采集软件是一款通用性互联网数据采集软件,今天的案例使用的是大众点评网,要抽取下面的翻页链接。
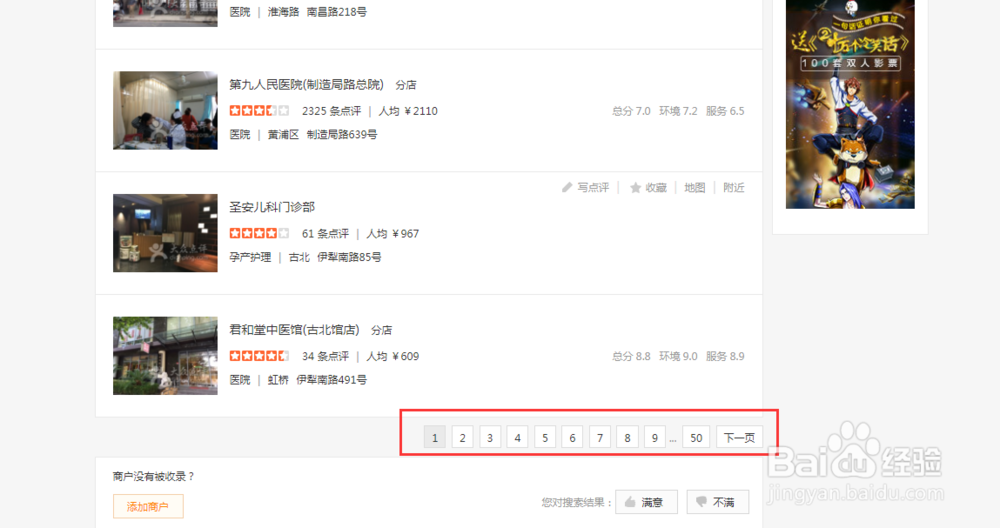
2、第一步先看每一页的链接地址有没有规律。
如图中第二页和第三页URL链接地址中最后面的数字表明了页码。

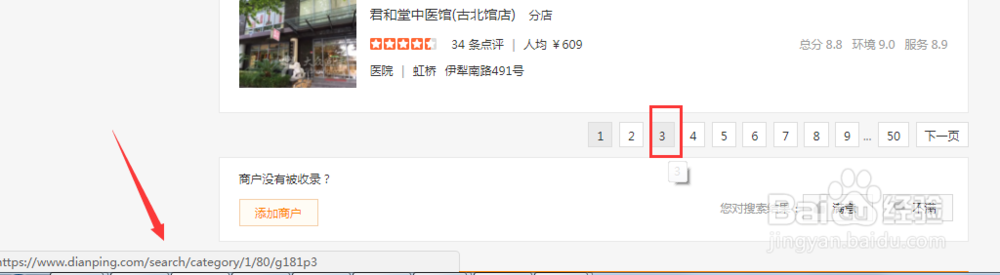
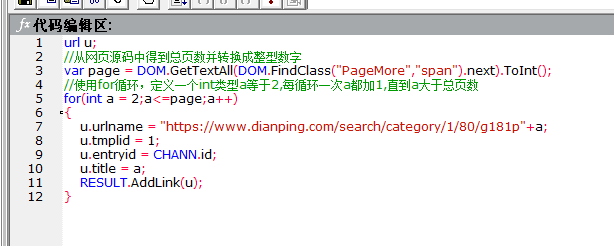
3、现在发现了url的不同点,我们可以通过拼接的方式得到所有翻页的链接地址。下面写了拼接第二页链接地址的脚本,图中是我写的一个简单的抽取链接的脚本,只能抽取一个链接,先给大家介绍一下每一行代码的作用,之后再补全抽取全部链接的功能。
第一行代码:定义一个url类的变量u
第二行代码:u.urlname是网页的链接地址,为其赋值
第三行代码:u.tmplid是这个链接抽取所要关联的模板id,这里是翻页,所以关联自身模板
第四行代码:这个链接抽取所对应的频道id
第五行代码:u.title是链接标题,为其赋值
第六行代码:将所拼接的链接添加到最后的结果中
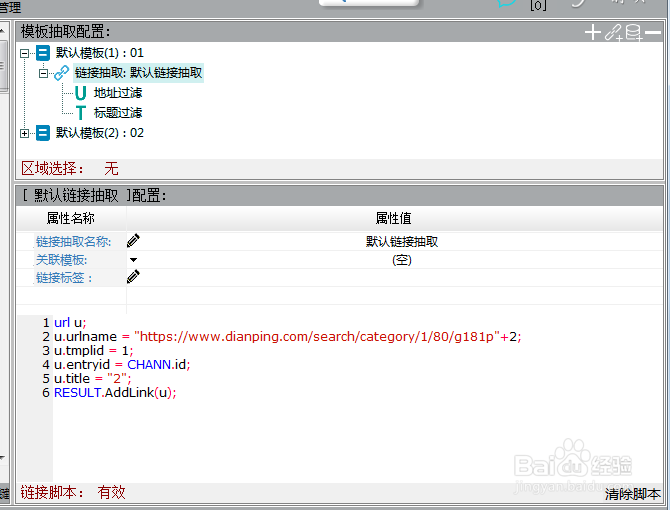
4、下面是加上了循环的脚本,这样就能抽取到所有的翻页。可以跟上一张图对比一下,看看加了什么代码。
5、脚本写完了,给大家看一下预览图,看看是不是把需要的链接全部都取到了。
今天的链接抽取教程就到这里,下次教程准备出一个数据抽取的教程,两个结合起来就能实现从网站上抓取数据的功能了。